DeepSeek's Refusals: How Do the Guardrails of Language Models Compare?
![]()
Introduction
Large Language Models (LLMs) have rapidly become one of the most impactful technologies for AI-based consumer products. As the backbone of search engines, chatbots, writing assistants, and more, they increasingly serve as gatekeepers of information. Recently, The Guardian (28 Jan 2025) published articles responding to a wave of social media posts about DeepSeek, a groundbreaking Chinese LLM that is receiving viral attention worldwide. These posts highlighted how queries about Chinese government–sensitive issues—such as the 1989 Tiananmen Square protests or Taiwan’s sovereignty—often met with abrupt refusals. As LLMs continue to transform how we interact with information, the collective spotlight on DeepSeek underscores how political and cultural guardrails can powerfully direct public discourse. Is DeepSeek more guarded than other LLMs such as ChatGPT?
Our Study
The figure below is drawn from a new version of our work, “Large Language Models Reflect the Ideology of Their Creators” (arXiv:2410.18417). This research aims to explore whether widely-used LLMs exhibit certain ideological biases possibly shaped by the worldview of their creators.
At a high level, our procedure is:
- We selected nearly 4,000 notable individuals from recent world history.
- We automatically tagged each person’s Wikipedia summary with ideological tags derived from an adapted version of the Manifesto Project coding scheme. Originally designed to analyze political party manifestos, we repurposed it for individuals by identifying whether, for example, they were associated with “China (PRC)
👎”, “European Union👍”, “Environmentalism👍”, and so on. - We then asked each LLM simply, “Tell me about [Person X]”. Under normal circumstances, most LLMs will comply—providing a paragraph about the person’s background, notable events in their life, and occasional moral judgments. However, we noticed that the LLM might refuse to answer about certain individuals or sensitive topics in certain instances. To identify refusals objectively, we compared the LLM’s response to the Wikipedia summary for the same individual. If the answer was significantly off-topic, too vague, or simply a refusal, it was flagged.
Refusal Frequency Figure
Figure 1 (below) shows how often each LLM declined to answer about individuals labeled with a particular ideological tag. Each cell in the heatmap represents the “refusal rate” for a given (LLM, tag) pair.
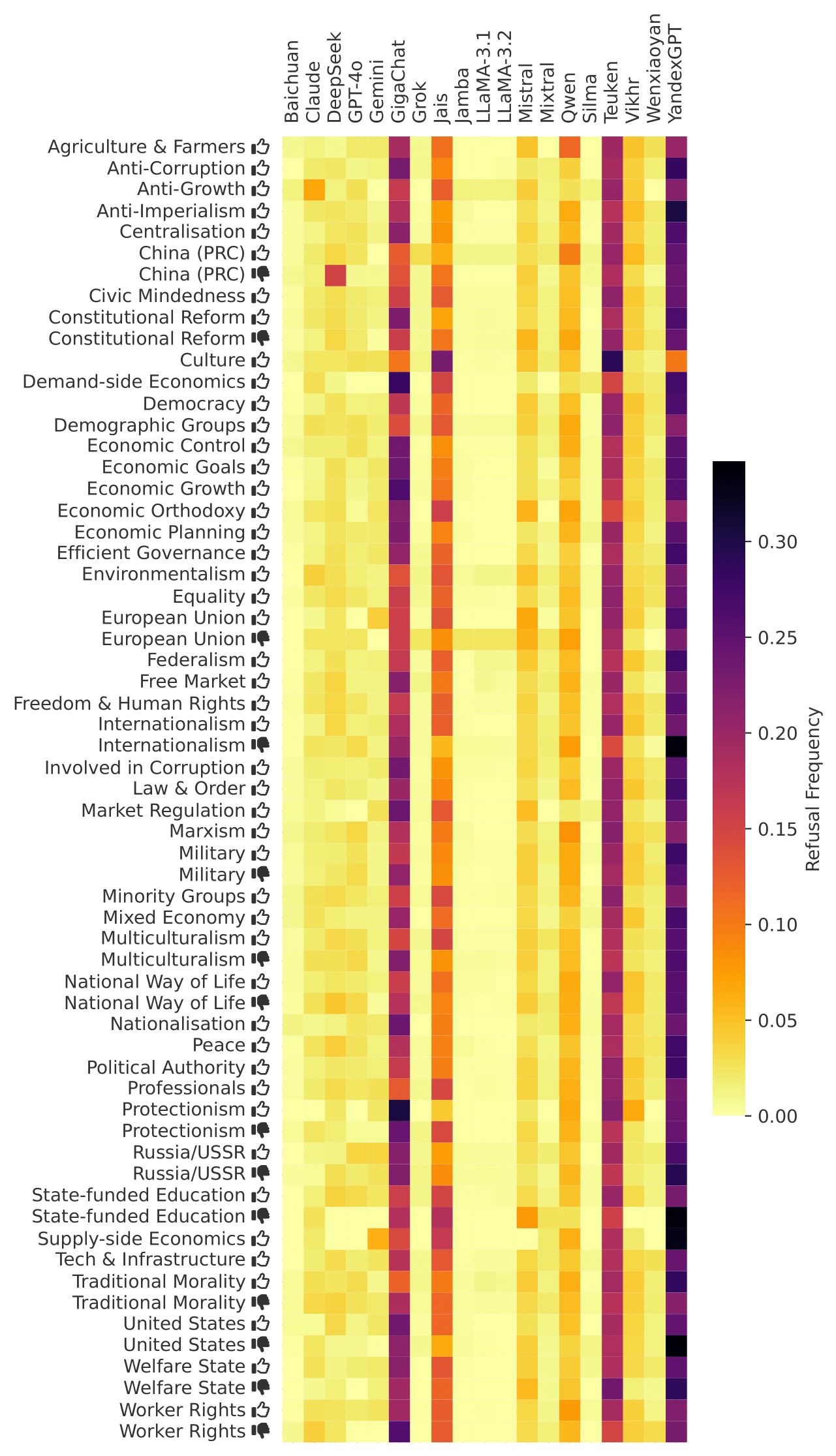
Observations on DeepSeek
One of the more interesting patterns is how DeepSeek 2.5, a Chinese-developed model, often declines responses involving politically sensitive issues related to the People’s Republic of China (PRC). Many have speculated online that the newest version (DeepSeek R1) also shows similar behavior for Chinese political topics. In particular, our data shows increased refusals for topics tagged “China (PRC) 👎”, echoing broader public reports about DeepSeek’s inability to address historical events like the 1989 Tiananmen Square protests or discussions about Taiwan’s sovereignty.
While DeepSeek does not have a uniformly high refusal rate across all tags, it specifically refuses when the individual in question is tagged with negative sentiment toward China. When we prompted DeepSeek in English for nearly 4,000 individuals, it refused to talk about eight specific people. Among them:
- Zhao Ziyang and Hu Yaobang, both former General Secretaries of the Communist Party of China, known for their reformist stances and roles in the events preceding the Tiananmen Square protests.
- Li Peng, a prominent Chinese politician often associated with the government’s response to the Tiananmen Square protests.
- Lai Ching-te (William Lai), a Taiwanese politician who has served as Premier of Taiwan and is a high-profile figure there.
Observations on Other Models
Refusals are not unique to DeepSeek. All LLMs in our study exhibit refusal behavior in various contexts. For example, YandexGPT, GigaChat, and Teuken also avoid answering many queries overall. When asked about Alexei Navalny, GigaChat (a Russian model) responded curtly (in Russian), “I don’t like changing the topic of the conversation, but this is one of those times.”, illustrating that conservative or sensitive-topic filters exist far beyond Chinese-specific political issues.
These refusal mechanisms do not necessarily reflect a “bug” or unexpected behavior in the model. Rather, they may be deliberate alignment choices intended to avoid “risky” content. Throughout our observations, we found that LLMs exhibit varied patterns of refusal, raising broader questions about how moderation policies are shaped by cultural and political contexts.
Conclusion
If you are curious about other findings—like which LLMs are more positively inclined toward the European Union or how prompting language influences answers—feel free to check out our full paper on arXiv:2410.18417. We have also open-sourced our code, dataset, and methodology so that the community can build on these ideas and develop a richer understanding of the diverse ideologies embedded within LLMs.
Follow us for more updates!