Artificial Intelligence and Data Analytics Research Group
Ghent University - IDlab
About AIDA
The Artificial Intelligence and Data Analytics (AIDA) group at Ghent University is led by Prof. Tijl De Bie. Currently, the group consists of 10 PhD students, 4 postdoctoral researchers, and 3 professors. The group is also part of the larger Internet Technology and Data Science Lab (IDLab) a joint research initiative between the University of Antwerp and Ghent University.
The research at AIDA covers a wide range of topics in the areas of Artificial Intelligence, Machine Learning and Data Science. More specifically, we conduct research on graph and text mining, representation learning, generative AI, recommender systems, fairness and bias, data visualization and music information retrieval. In addition to writing research papers, we also valorise the most promising ideas via spin-off companies such as Nobl.ai.
The group is currently funded by Prof. De Bie’s FWO Odysseus Type 1 Grant, the European Research Council grant "Vigilia", the Flemish Government under the "Onderzoeksprogramma Artificiële Intelligentie (AI) Vlaanderen" programme, FWO and BOF Individual Fellowship Grants, and several FWO projects.
If you are interested in learning more about us or joining our group, please check out our Contact section!
News & Events
Featured news and events organized by AIDA. For other news and research articles, head to our Blog!
We have broad expertise in ML, AI, and Data Mining. Specific topics we have made substantial contributions to include:
Large Language Models
Data Exploration and Visualization
AI Safety and Ethics
AI for HR and the Labour Market
Recommender Systems
Graph Mining
Research Output
Here is a list of our most recent publications, along with a selection of featured projects. The open-source code and data for our projects can be found on our GitHub and HuggingFace pages.
Are you passionate about Machine Learning and Data Mining and want to pursue an academic career? Then consider joining our Team! We always have open positions, like these:
Multiple PhD Positions - ERC Project Vigilia
Contact Us
We currently have PhD and Postdoc opened positions, if you want to join our team contact us at:
tijl.debie@ugent.be
Large Language Models
Large language models represent a significant advancement in natural language processing. These models are designed to perform general-purpose language generation and other language-related tasks. Their capabilities stem from extensive training on vast amounts of textual information, which allows them to learn statistical relationships and patterns inherent in human language [1].
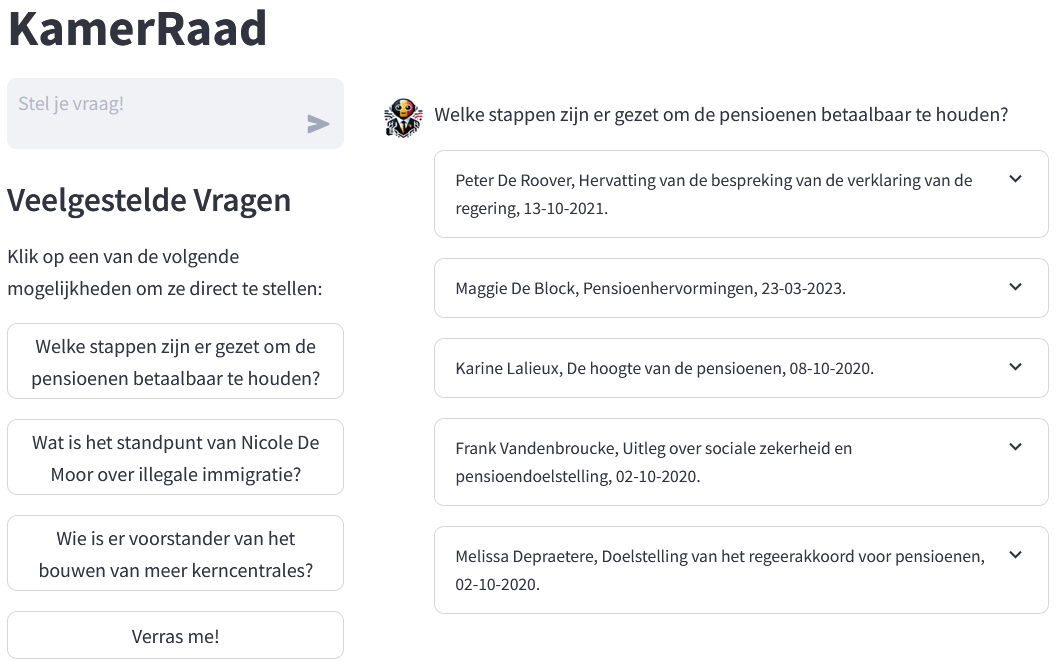
Within the AIDA research group, we are training, finetuning and applying large language models for a variety of tasks. For instance, we are developing LLM-based tools trained on political data to suppors voters in making well-informed decisions [2]. We are also harnesing the power of language models to understand job market data [3] as well as studying the inherent political biasses in these types of systems.
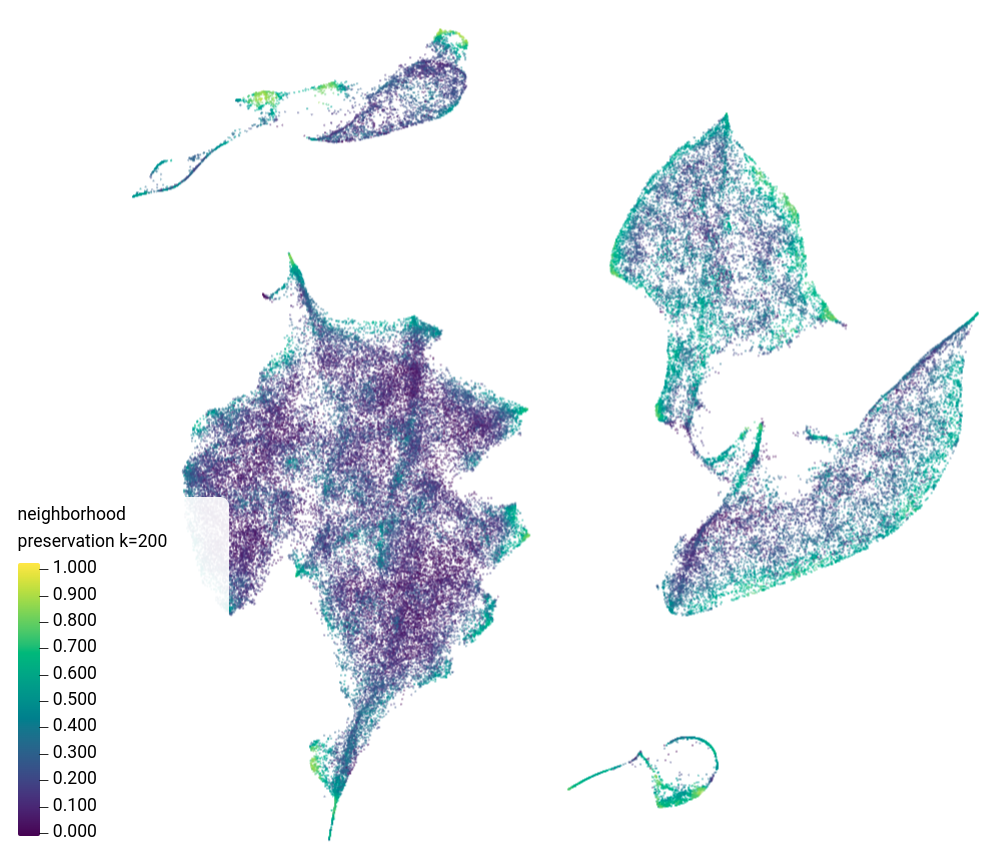
Data visualization is the graphic representation of information. The goal is to produce images that communicate the relations among the represented data entities to the viewers [1]. However, getting direct insights from large high-dimensional data is challenging. One way to glean insight on the overall structure is to visualize the data in 2D using dimensionality reduction algorithms. These methods are widely used with great efficacy. Nevertheless, existing methods are based on the assumption that there is a 2D structure in the data, which is rarely true. Hence, methods yield results of mixed quality. Pattern mining can augment dimensionality reduction by discovering interesting patterns or structures in data, such as clusters, associations, or anomalies. Interactive analytics, where data analysts work in tandem with visualization and pattern mining tools can help to identify interesting patterns and explain the results.
In the AIDA group, we have developed methods to incorporate prior knowledge into the dimensionality reduction process, leading for example to Revised Conditional t-SNE [2] and Topological Regularized Data Embeddings [3]. Additionally, the group has developed techniques for finding defining attributes for subsets of the data and computing interpretable clusterings. A key focus of our group is to make dimensionality reduction more interactive and interpretable, allowing for a deeper understanding of the data and the relationships between data points.
AI systems are increasingly considered for deployment in high-stakes decision making processes, like in deciding whether someone should be recruited for a job, whether they should receive a loan, or whether they should be kept in jail. These decisions are expected to respect fundamental rights when they are made by humans. AI systems are now held up to a similar standard in the field of AI ethics, including principles like privacy, transparency, explainability, and more [1].
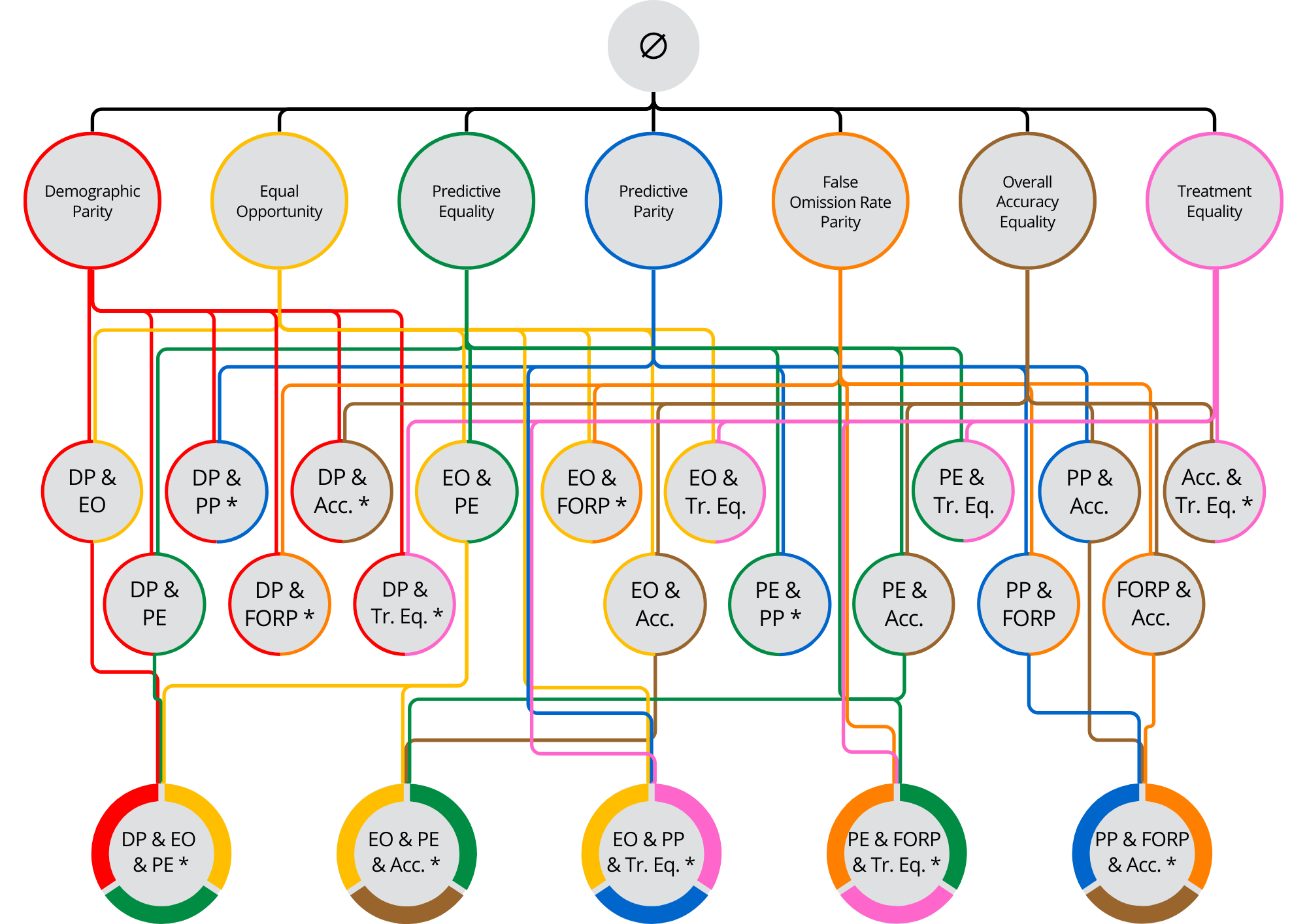
In particular, our group is interested in the right to non-discrimination. This principle is studied in the field of AI fairness and is concerned with measuring and mitigating algorithmic bias. Typically, such bias is formally quantified as a disparity between statistics computed for different demographic groups. Our group explores the definitions of those statistics [3], their underlying structure, and their (in)compatibilities [2]. Additionally, we construct tools to mitigate these biased disparities in tasks like binary classification [3][4] and recommendation [5]. Yet, we also consider the limitations of such formal, technical solutions in truly making an automated decision process fair.
Beyond fairness, our group has worked on explainability in data mining and trust in content moderation.
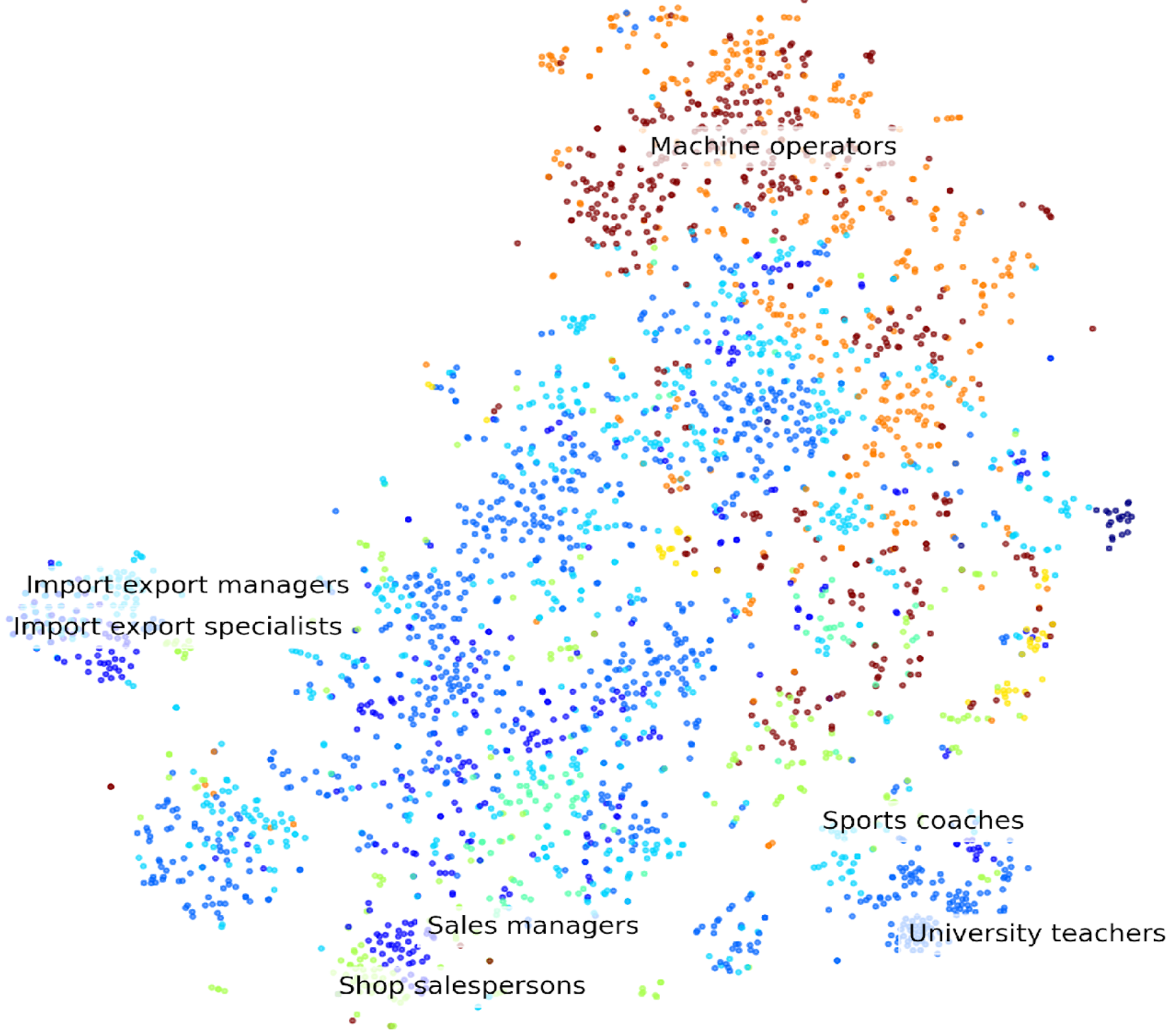
Artificial Intelligence (AI) has the potential to revolutionize the job market and transform the field of Human Resources (HR), yet its application in these domains has been largely overlooked. AI models can help us better understand the current state of job markets as well as predict their evolution. It can enhance recruitment by efficiently matching candidates with job requirements and providing personalized recommendations. It can automate administrative tasks, predict employee retention, and promote diversity and inclusion. AI models can also supports learning and development, employee engagement, and performance management.
In the AIDA research group we explore, analyze, and standadize job market data via tools such as the SkillGPT ESCO tagging model [2]. We are also working on models to help users navigate the job market maze by providing career path recommendations, education recommendations, job recommendations, etc.
Recommendation systems are computer algorithms that help predict and suggest items or content that users might be interested in based on their past behaviours, preferences, and similarities with other users [1]. These systems use various techniques such as collaborative filtering, content-based filtering, and hybrid approaches to create personalized recommendations across a wide range of domains, including e-commerce, streaming services, social media, human resources, and more. By analyzing user interactions and feedback, recommendation systems not only improve user experience by providing relevant suggestions but also serve as valuable tools for businesses to increase customer engagement, satisfaction and ultimately drive revenue through personalized and targeted recommendations.
In the AIDA research group, we work on various aspects of recommendation systems in different domains such as the job market, music recommendation, item recommendations, etc. We not only design methods to improve the predictive accuracy of the recommendations but also to enhance beyond accuracy measures such as diversity and coverage of items in the generated recommendations. We develop novel methods and frameworks to achieve high performance for specific problems in recommendation systems such as the congestion problem [2].
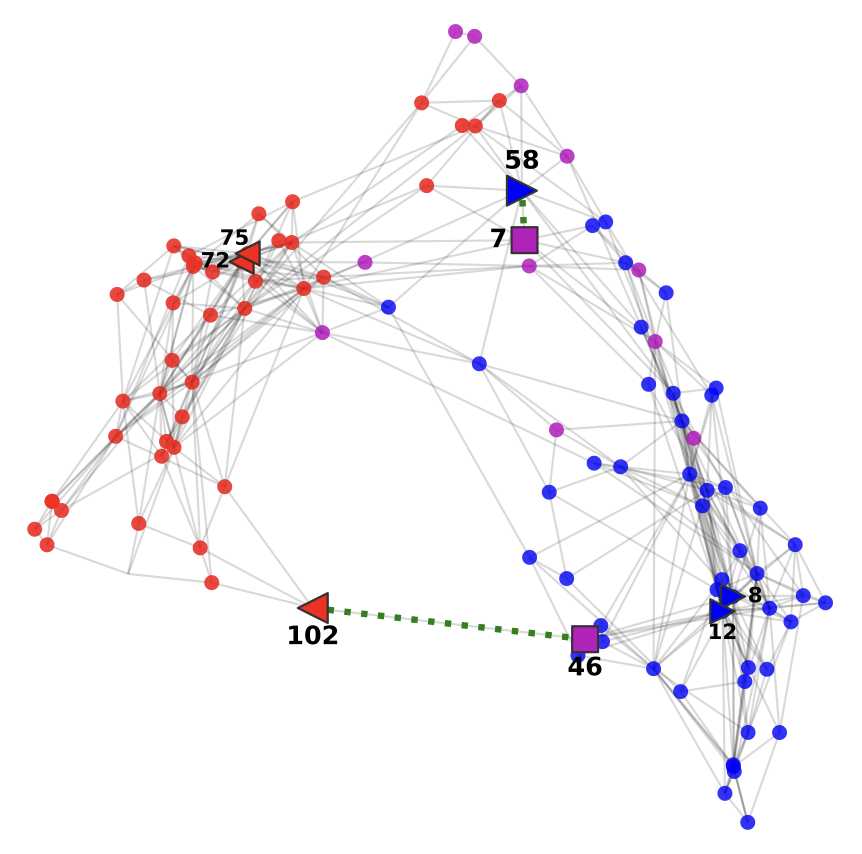
In numerous real-world scenarios, complex interactions among entities are often best conceptualized through graphs, where objects are nodes interconnected by edges. Graphs serve as a foundational data structure across various domains, including computational social sciences, recommender systems, epidemiology, biology, and neurosciences, among others [1].
Within our research group, we have studied extensively the problem of graph embedding, a fundamental task aimed at representing graph nodes as vectors in a lower-dimensional space. This process allows for the extraction of essential structural information from graphs with applications in downstream tasks such as Link Prediction and Node Classification .
Furthermore, recognizing that real-world graphs are dynamic and evolve over time, we have expanded our focus to incorporate temporal aspects. By leveraging techniques such as Point Process modeling and Survival Analysis, we’ve developed statistical techniques for analyzing Dynamic Graphs, where the temporal dimension enriches our understanding and predictive capabilities [3].
The AIDA-IDLab-research group has multiple fully-funded open research fellowships at predoctoral level in the context of the ERC Advanced Grant VIGILIA, with Prof. Tijl De Bie as principal investigator. The project aims to develop radically innovative AI-based approaches to mitigate the effects of so-called mis-, dis-, and malinformation, while safeguarding the fundamental right of freedom of expression and of information.
Eligible candidates (will) hold a recent Master’s degree, covering one or several of the following areas: Artificial Intelligence, Large Language Models, knowledge graphs, cognitive science, behavioral economics.
For more information on the positions, the conditions and requirements, the offer, and how to apply, please see this LINK.
🚀 Please help us spread the word! 🚀
AI4WORK Workshop
The job market of the 21st century poses a set of unique challenges. Automation through AI and other disruptive technologies will result in unprecedented shocks in the job market, with entire job categories disappearing while new types of jobs requiring new skills and competencies will emerge. While such shifts in the job market have happened before, the impact of the ongoing revolution may be larger and will unfold much faster than it did in the previous industrial revolutions. To mitigate the impact of this disruption, large parts of the workforce will need upskilling and retraining in a matter of years, and continuously thereafter.
The AI4Work workshop aims to study how to address the challenges of this new job market by means of data-driven solutions that better enable the different actors to achieve their goals, including job seekers, employers, HR agencies, policy makers, training facilities, government agencies, and more. The challenges for which data science can make a genuine difference are numerous. For example: Workers need better job recommendations and career advice. Employers need better HR and recruitment strategies, with due consideration of ethical constraints. Policy makers need to understand how to regulate the job market to ensure efficiency, fairness, and inclusion. And so on.
Fairness in Machine Learning continues to be a growing area of research and is perhaps now more relevant than ever, as the popularity of Generative Large Multimodal Models continues to grow, new AI-powered applications and tools are being widely used by the public, and legal regulations of AI/ML (e.g., the EU AI Act) are close to being adopted. While initial studies on fair ML and AI bias often focused on the technical aspects behind discriminatory algorithms and on treating fairness as an objective to be optimized, more recent work is recognizing the importance of looking at fairness from a broader perspective, taking legal and societal implications into account and involving different stakeholders in the design process of fair algorithms.
Data mining algorithms allow us to make sense of large quantities of data and obtain insights from it. This includes mining from different kinds of data, including tabular, sequence, time series, graph, etc.
Classic algorithms are often designed for a specific, often narrow, task (i.e., task-centered), yet do not take into account the specific goals of the users (which may well differ from user to user). For instance, when looking for outputs useful for automating a decision process, the data mining algorithm user may look for patterns that do not go against their prior knowledge. Oppositely, another user may look for ‘surprising’ outputs when their goal is to understand previously unknown phenomena (knowledge discovery).
However, most existing data mining algorithms can only be customised to the extent allowed by their pre-defined parameters, which are not guaranteed to be able to align with the users’ needs. Furthermore, specifying preferences via parameters often requires extensive data mining expertise. This is often not the case in the application domains, where users tend to be domain experts with knowledge about the source of the data.
Recently, researchers in the data mining field have turned their attention towards integrating users in the mining process, trying to take into account both their priors and their goals. However, current approaches tend to model users in ways that are closely tied to the specific task requirements, limiting their generalisability. As such, there is not one recipe that can be applied to data mining tasks in general. At a higher level, it is unclear how user needs and domain expertise can be modelled so as to improve data mining approaches.
The goal of this workshop is to bring together researchers and practitioners from (interactive) data mining, interpretable machine learning, data visualization, human-computer interaction, active learning, machine teaching, and cognitive science, and to facilitate the discussion between experts to identify and formalise the problem of integrating human preferences and situation-specificness in data mining approaches. We aim to foster discussions about the key research questions/challenges, including but not limited to:
How can we rigorously define the goal of incorporating the human (in an interactive manner) in the data mining process?
How can we categorize existing algorithms and use cases with respect to how human feedback may be incorporated?
How to evaluate algorithms that rely on human feedback? Can the effect of human guidance be measured reliably in a benchmark setting?
How can we empower users to guide algorithm outputs toward their goals or preferences in a user-friendly way? Is there a principled way to incorporate user preferences into the algorithm?
We specifically encourage submissions/discussions on the topic of issues encountered when applying (interactive) data mining to real-world use cases, as well as innovations towards solving those issues. We hope that this will inspire future collaborations, both to solve specific research problems, and to steer the community on the subject of human-centered data mining.
We recently held a Mini-Workshop on AI for HR and Employment Services to explore how artificial intelligence (AI) can help improve the future of work. The job market is changing quickly, and both HR professionals and employment services need new tools to keep up with these changes.
In today’s world, AI can be used to make many tasks easier and more efficient. For example, AI can help match job seekers with the right jobs, assist employers in finding the best candidates, and even help policymakers make fairer decisions about job markets. In the workshop, we discussed how AI can solve real-world challenges in HR and employment services.
The job market of the 21st century poses a set of unique challenges. Automation through AI and other disruptive technologies will result in unprecedented shocks in the job market, with entire job categories disappearing while new types of jobs requiring new skills and competencies will emerge. While such shifts in the job market have happened before, the impact of the ongoing revolution may be larger and will unfold much faster than it did in the previous industrial revolutions. To mitigate the impact of this disruption, large parts of the workforce will need upskilling and retraining in a matter of years, and continuously thereafter.
The AI4HR&PES workshop aims to study how to address the challenges of the contemporary job market and human resources management by means of data-driven solutions that better enable the different actors to achieve their goals, including the job seekers, employers, HR agencies, policy makers, training facilities, government agencies, and more. The challenges for which data science can make a genuine difference are numerous. For example: Workers need better job recommendations and career advice. Employers need better HR and recruitment strategies, with due consideration of ethical constraints. Policy makers need to understand how to regulate the job market to ensure efficiency, fairness, and inclusion. And so on.
Fairness in Machine Learning continues to be a growing area of research and is perhaps now more relevant than ever, as the popularity of Generative Large Multimodal Models continues to grow, new AI-powered applications and tools are being widely used by the public, and legal regulations of AI/ML (e.g., the EU AI Act) are close to being adopted. While initial studies on fair ML and AI bias often focused on the technical aspects behind discriminatory algorithms and on treating fairness as an objective to be optimized, more recent work is recognizing the importance of looking at fairness from a broader perspective, taking legal and societal implications into account and involving different stakeholders in the design process of fair algorithms.
Over the past decade, concerns about the societal risks posed by AI systems have been steadily growing. AI systems have already been known to reinforce discriminatory biases, violate privacy, and manipulate public discourse. A wealth of technical work has been produced to assess and mitigate those risks, yet it is often based on simplistic assumptions of the role that AI plays in the real world.
The goal of this symposium is to tighten the link between technical viewpoints on the societal risks of AI and those from industry, law and policy. Hence, top experts in Belgium representing these diverse viewpoints, from within academia and without, will present their work and the challenges they face in addressing the societal risks of AI. Afterwards, they will participate in a panel discussion.
The invited speakers are:
Toon Calders (University of Antwerp)
Jelle Hoedemaekers (Agoria)
David Martens (University of Antwerp)
Felicity Reddel (The Future Society)
Katrien Verbert (KU Leuven)
Following the symposium, Maarten Buyl will hold his public PhD defense on the topic of AI fairness. His thesis proposes technical tools to mitigate algorithmic bias and discusses the limitations of technical tools in truly achieving fair decision processes. The presentation is aimed at a non-expert audience.
DBWRS is the first Dutch-Belgian Workshop on Recommender Systems. In today’s digital age, where information overload and an abundance of choices are the norm, recommender systems play a vital role in helping users navigate through vast amounts of data. These systems have become ubiquitous across various domains, including e-commerce, social media, entertainment, and many more, shaping the way we discover new products, engage with content, and connect with others.
DBWRS will bring together researchers and practitioners from diverse fields to explore and discuss the latest advancements, challenges, and opportunities in this dynamic field. By fostering collaboration and exchange of ideas among experts in computer science, data science, artificial intelligence, psychology, communication, policy, law and beyond, this workshop aims to unlock new frontiers and push the boundaries of recommender systems.
We invite you to join us in this exciting journey as we explore the interdisciplinary nature of recommender systems and work together to uncover innovative approaches that enhance user experiences, foster personalized decision-making, and contribute to the ever-evolving landscape of digital recommendations.
The job market of the 21st century poses a set of unique challenges. Automation through AI and other disruptive technologies will result in unprecedented shocks in the job market, with entire job categories disappearing while new types of jobs requiring new skills and competencies will emerge. While such shifts in the job market have happened before, the impact of the ongoing revolution may be larger and will unfold much faster than it did in the previous industrial revolutions. To mitigate the impact of this disruption, large parts of the workforce will need upskilling and retraining in a matter of years, and continuously thereafter.
The AI4HR&PES workshop aims to study how to address the challenges of the contemporary job market and human resources management by means of data-driven solutions that better enable the different actors to achieve their goals, including the job seekers, employers, HR agencies, policy makers, training facilities, government agencies, and more. The challenges for which data science can make a genuine difference are numerous. For example: Workers need better job recommendations and career advice. Employers need better HR and recruitment strategies, with due consideration of ethical constraints. Policy makers need to understand how to regulate the job market to ensure efficiency, fairness, and inclusion. And so on.
The AI in Manufacturing workshop brings together researchers and practitioners from AI and the area of manufacturing, and especially also people working at the intersection. The workshop provides an opportunity for interaction and networking, and a platform for the dissemination of problem statements, early ideas and work-in-progress presentations for potentially ground-breaking research, in the broad area of AI with application in manufacturing. Our intention is to facilitate AI advances relevant for manufacturing. The scope includes theory, algorithms, systems, and applications related to this topic.
We are co-organizing BNAIC/BeNeLearn, the reference AI & ML conference for Belgium, Netherlands & Luxembourg. The combined conference will take place from November 7th till November 9th in Mechelen, Belgium and is organized by the University of Antwerp, under the auspices of the Benelux Association for Artificial Intelligence (BNVKI) and the Netherlands Research School for Information and Knowledge Systems (SIKS).
The job market of the 21st century poses a set of unique challenges. Automation through AI and other disruptive technologies will result in unprecedented shocks in the job market, with entire job categories disappearing while new types of jobs requiring new skills and competencies will emerge. While such shifts in the job market have happened before, the impact of the ongoing revolution may be larger and will unfold much faster than it did in the previous industrial revolutions. To mitigate the impact of this disruption, large parts of the workforce will need upskilling and retraining in a matter of years, and continuously thereafter.
The FEAST workshop aims to address the challenges of the contemporary job market and human resources management by means of data-driven solutions that better enable all relevant stakeholders to achieve their goals in a fair, effective, and sustainable manner, including the job seekers, employers, HR agencies, HR managers, policy makers and government agencies, training facilities, and more. The challenges for which data science can make a genuine difference are numerous: Workers need better job recommendations and career advice; Employers need better HR and recruitment strategies, with due consideration of ethical constraints; Policy makers need to understand how to regulate the job market to ensure efficiency, fairness, and inclusion; And much more.
The AI in Manufacturing workshop brings together researchers and practitioners from AI and the area of manufacturing, and especially also people working at the intersection. The workshop provides an opportunity for interaction and networking, and a platform for the dissemination of problem statements, early ideas and work-in-progress presentations for potentially ground-breaking research, in the broad area of AI with application in manufacturing. Our intention is to facilitate AI advances relevant for manufacturing. The scope includes theory, algorithms, systems, and applications related to this topic.
The job market of the 21st century poses a set of unique challenges. Automation through AI and other disruptive technologies will result in unprecedented shocks in the job market, with entire job categories disappearing while new types of jobs requiring new skills and competencies will emerge. While such shifts in the job market have happened before, the impact of the ongoing revolution may be larger and will unfold much faster than it did in the previous industrial revolutions. To mitigate the impact of this disruption, large parts of the workforce will need upskilling and retraining in a matter of years, and continuously thereafter.
The FEAST workshop aims to address the challenges of the contemporary job market and human resources management by means of data-driven solutions that better enable all relevant stakeholders to achieve their goals in a fair, effective, and sustainable manner, including the job seekers, employers, HR agencies, HR managers, policy makers and government agencies, training facilities, and more. The challenges for which data science can make a genuine difference are numerous: Workers need better job recommendations and career advice; Employers need better HR and recruitment strategies, with due consideration of ethical constraints; Policy makers need to understand how to regulate the job market to ensure efficiency, fairness, and inclusion; And much more.
In 2021, we hosted in the beautiful city of Ghent an ECML-PKDD satelite event gathering more than 100 attendees from Belgium, France, the Netherlands and Germany. The event gave researchers the opportunity to network and at the same time to follow the sessions of the virtual ECML-PKDD conference.
ECML-PKDD 2020
We have organized the 2020 edition of ECML-PKDD. ECML-PKDD is the premier European machine learning and data mining conference that builds upon over 18 years of successful events and conferences held across Europe. In 2020, ECML-PKDD was due to take place in Ghent, Belgium. However, owing to the COVID-19 pandemic, the conference was held virtually. The video presentations and papers are freely available on the official website.
We are co-organizing an international workshop on Applications of Topological Data Analysis, within the context of ECML-PKDD, on Monday 16 September 2019.
Workshop chairs:
Robin Vandaele Ghent University
Tijl De Bie Ghent University
John Harer Duke University
Automating Data Science
We are co-organizing an international workshop on Automating Data Science, within the context of ECML-PKDD, on Friday 20 September 2019.
Workshop chairs:
Tijl De Bie (UGent, Belgium)
Luc De Raedt (KU Leuven, Belgium)
Jose Hernandez-Orallo (Universitat Politecnica de Valencia, Spain)
Graph Embedding and Mining
We are co-organizing an international workshop on Graph Embedding and Mining, within the context of ECML-PKDD, on Monday 16 September 2019.
Workshop chairs:
Bo Kang Ghent University
Rémy Cazabet Université de Lyon
Christine Largeron Université Jean Monnet
Polo Chau Georgia Institute of Technology
Jefrey Lijffijt Ghent University
Tijl De Bie Ghent University
Automating Data Science
We co-organized a Dagstuhl workshop on Automating Data Science, September 30-October 5, 2018.
Workshop chairs:
Tijl De Bie (Ghent University, BE)
Luc De Raedt (KU Leuven, BE)
Holger H. Hoos (Leiden University, NL)
Padhraic Smyth (University of California – Irvine, US)
Opinions, Conflict, and Abuse in a Networked Society (OCEANS)
Opinions, Conflict, and Abuse in a Networked Society (OCEANS) is an ACM SIGKDD 2018 workshop that we are co-organizing. It is going to take place in London, UK, on August 20, 2018.
Description: Disruptive technological innovations affect what lies at the heart of the fabric of our society: how people interact with each other, what they think to be true or false, and what they value as right or wrong. Indeed, concepts such as post-truth-society, filter bubbles, and echo chambers are very recent terms, and online social interactions have proven more prone to abusive and anti-social behaviors than real-world interactions. While we are starting to see the challenges posed by the pervasive adoption of these technologies, society has no answers yet.
We contend that answers to these new challenges will require a transdisciplinary approach, involving social scientists, physicists, mathematicians, computer scientists, as well as close collaboration between academic researchers, industry practitioners, and relevant government agencies. This workshop is targeted at the KDD community, and aims to chart out the area from a KDD perspective, while bringing in insights from other areas and sharing state-of the-art technologies and best practices.
Jefrey Lijffijt – Yesterday I organised the Workshop on Interactive Data Exploration and Analysis (IDEA) in Halifax, Canada, as a side-event of the ACM SIGKDD Conference, the world-premier conference in data mining and knowledge discovery. The workshop was a great success, with three keynote speakers and twelve presentations and posters about new research that we selected after peer-review. The topic of the workshop aligns perfectly with the topic of my FWO Pegasus project, which is “Personalised, interactive, and visual exploratory mining of patterns in complex data”. This niche of data science sits at the interface of data mining, machine learning, human-computer interaction, and data visualisation, and is currently rapidly attracting more attention from the scientific community.
The major premise of this line of work is to transform the job of data scientists and data-intensive science, not by automating away analysis completely, but by building more intuitive, efficient, and effective tools to explore and analyse data. Ultimately, the possibility to analyse data should also become accessible to laypersons, e.g., for journalists or experts of other scientific domains that do not have years of training in programming and statistics. An aim also referred to as the democratisation of data and analytics. To achieve this requires scientists from different fields to collaborate, because the open problems range from cognition and interface design to statistics and computational complexity. My own background is in the latter two.
I am really happy to have received a Pegasus grant. I intentionally applied with a high-risk proposal, to work on a topic that is completely new and still in the margin of my field. Now, I have three years will almost no other obligations to grow both my expertise into the related domains, as well as to build prototypes of tools to show the potential of the ideas. I chose Ghent University as a host for the project, because Prof. Tijl De Bie from the IDLab is a world-wide expert on the computational aspects of data exploration and analysis. His group is also well-funded (ERC Consolidator and FWO Odysseus grants) so there are PhD students and other post-docs that can help me achieve these goals. I am deeply grateful for their support.
Data Mining: Beyond the Horizon was a workshop to discuss and work towards where the participants think the field of data mining should be headed. Beyond the Horizon took place in Bristol, UK, from Wed 19 – Fri 21 November 2014.
The goal of the workshop was two-fold:
Open-ended: to exchange thoughts about the challenges and opportunities for our generation of data mining researchers, and to establish future-proof visions.
Goal-oriented: to facilitate short-, medium-, and long-term collaborations among the participants, including joint project proposals, papers, co-organized workshops, tutorials, etc.
Attendance at Beyond the Horizon was by invitation only. To keep it small and effective as a workshop, only a limited number of researchers was invited to participate.
The European Summer School on Artificial Intelligence (ESSAI) is a direct product of European AI research being increasingly coordinated and scaled up across projects, research organisations and countries. ESSAI’s immediate predecessors are the Advanced Course on AI (ACAI), organised since 1985 under the auspices of the European Association for Artificial Intelligence (EurAI), and the TAILOR Summer School on Trustworthy AI organised since 2021 by the European ICT-48 Network of Excellence on Trustworthy AI through Integrating Learning, Optimisation and Reasoning. Last year, these two schools were already co-located in Barcelona with two parallel tracks as well as joint events.
This year EurAI and TAILOR have continued their collaboration to deliver a significantly larger event with over 30 courses and tutorials presented in seven parallel tracks. ESSAI & ACAI-2023 will take place at the Faculty of Computer and Information Science, University of Ljubljana. ACAI-2023 will offer 10 invited tutorials (of 2x90min each) on the topic of AI & Science, while ESSAI-2023, together with the third TAILOR Summer School, will offer 24 courses (of 5x90min each) on all topics of AI, solicited through an open call for course proposals and selected by an international program committee.
The increasingly central role of data in today’s economy, as well as in data-driven research (e.g. the digital humanities, medicine, biology), has brought to the fore important questions around data ownership, data protection, privacy, and fairness of data-driven algorithms. This course covers the technical and legal aspects of how to ensure data science approaches can be trusted to treat individuals fairly and with consideration for privacy. Trust is achieved when ethical practices in data science are followed.
This is a specialist course organized in the context of the UGent doctoral schools of Engineering and Natural Sciences. This course will be of interest to researchers into data science algorithm design as well as to researchers working with personal data; the target group will include computer scientists, electrical and biomedical engineers, bioinformaticians, neuroinformaticions, medical informaticians, statisticians, molecular biologists, and other researchers and developers.The summer school will be open to graduate students, PhD students, postdoctoral researchers and early-career professionals in any field related to data science.
Data science is a field that is rapidly growing in importance due to a rapid growth of available data, computing power, and recent algorithmic developments. This poses obvious risks to the privacy of the data subjects, and to data protection more generally. However, it also entails two complementary opportunities. First, it may result in more effective decisions based on e.g. advanced machine learning techniques. Second, it makes it possible to also formalize ethical constraints regarding e.g. fairness and (paradoxically) also privacy, which can then be enforced on those data-driven decisions. Both of these opportunities are intimately tied to the increased accessibility of data, and are undeniably beneficial. For example, today judges still make their verdicts based on a combination of the facts, a subset of the law and jurisdiction, and (often unconsciously) personal biases. Doctors still make decisions based on their (limited) expert knowledge, the symptoms, combined with personal intuition. The increased availability of data well beyond personal anecdotal experience can not only reveal the existence of personal biases or intuition, it can also ensure the decisions are in accordance with ethical and legal constraints, while also improving those decisions in making them more evidence-based.
Formalizing ethical and legal constraints is however non-trivial, and research has only recently started to substantially invest in these questions. Yet, providing a constructive answer to these questions is a prerequisite for data science approaches to deserve the trust of its users. This specialist course should be of interest to anyone performing or using data science research broadly defined.
The presentation given at Facebook research in August 2018 can be found here.
Tutorial: Mining Subjectively Interesting Patterns in Data
Jefrey Lijffijt and Tijl De Bie will give a tutorial on mining ‘Subjective Interesting’ patterns in data at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Dublin, September 2018.
Title:
Mining Subjectively Interesting Patterns in Data
Abstract:
The problem of formalizing interestingness of data mining results remains an important challenge in data mining research and practice. While it is widely recognized as a challenge in frequent pattern mining, in this tutorial we will explain that it also manifests itself in other data mining tasks such as dimensionality reduction, graph mining, clustering, and more. This tutorial aims to introduce the audience to a relatively new framework for addressing these challenges in a rigorous and generic manner. This framework is the result of the ERC project FORSIED (Formalizing Subjective Interestingness in Exploratory Data Mining), which has by now resulted in a body of work of sufficient maturity to make a well-rounded tutorial possible and useful to colleague researchers as well as practitioners.
Outline:
Part 1: Introduction and motivation (15mins)
Part 2: The FORSIED framework (40mins)
Part 3: Binary matrices, graphs, and relational data (45mins)
COFFEE BREAK (20mins)
Part 4: Numeric and mixed data (55mins)
Part 5: Advanced topics, outlook & conclusions (30mins)
Q&A (15mins)
Tutorial: Making Sense of (Multi-) Relational Data
Tutorial on ‘Making Sense of (Multi-) Relational Data’ at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Porto, Portugal 2015.
PART I: Mining relational data — an overview (40 mins)
Data types: Codd’s relational data model, triple stores (linked data), networks, n-ary relations
Pattern syntax
Algorithmic approach (e.g. exhaustive enumeration or not)
`Supervised’ or not, or in between
Interestingness measures
PART II: Exploration through targeted modelling (20 mins)
Safarii
RDB-Krimp
(Probabilistic) ILP
PART III: Exploration by descriptive modelling – semi-relational local algorithms (20 mins)
Frequent itemset mining on the join
SMuRFIG
— BREAK
PART IV: Exploration by descriptive modeling – fully-relational local algorithms (40 mins)
N-set mining
RMiner \& variants
Constraint programming for closed relational sets
Uncovering the plot
PART V: Exploration by descriptive modeling – fully-relational global algorithms (40 mins)
Joint matrix-tensor factorisations
PART VI: Perspectives (20 mins)
General conclusions and recommendations
Open problems and opportunities